PDFファイルから元の画像を抽出する方法
前書き
PDFは、最も一般的に使用されるドキュメントタイプの1つです。場合によっては、PDFファイルからの画像が必要な場合があり、PDFファイルでスクリーンショットを作成して画像を取得できますが、そのアプローチを使用して取得するのは元の画像ではありません。さらに悪いのは、画像の数が多いと時間がかかることです。このチュートリアルは、PDFファイルから元の画像を抽出するための完璧なソリューションを提供します. ソフトウェアをインストールする必要はありません & ファイルのセキュリティが危険にさらされることを心配する必要はありません.
ツール: PDF画像を抽出する. Chrome、Firefox、Safari、Edgeなどの最新のブラウザ。
ブラウザの互換性
- FileReader、WebAssembly、HTML5、BLOB、ダウンロードなどをサポートするブラウザー。
- これらの要件に恐れることはありません。最近5年間のほとんどのブラウザは互換性があります
操作手順
- 最初にWebブラウザーを開き、次のいずれかを実行すると、以下の画像のようにブラウザーが表示されます。
- オプション 1: 次のように入力します "https://ja.pdf.worthsee.com/pdf-images" として表示 #1 下の画像で または;
- オプション 2: 次のように入力します "https://ja.pdf.worthsee.com", 次に開きます PDF画像を抽出する ツール ナビゲートすることによって "PDFツール" => "PDF画像を抽出する"
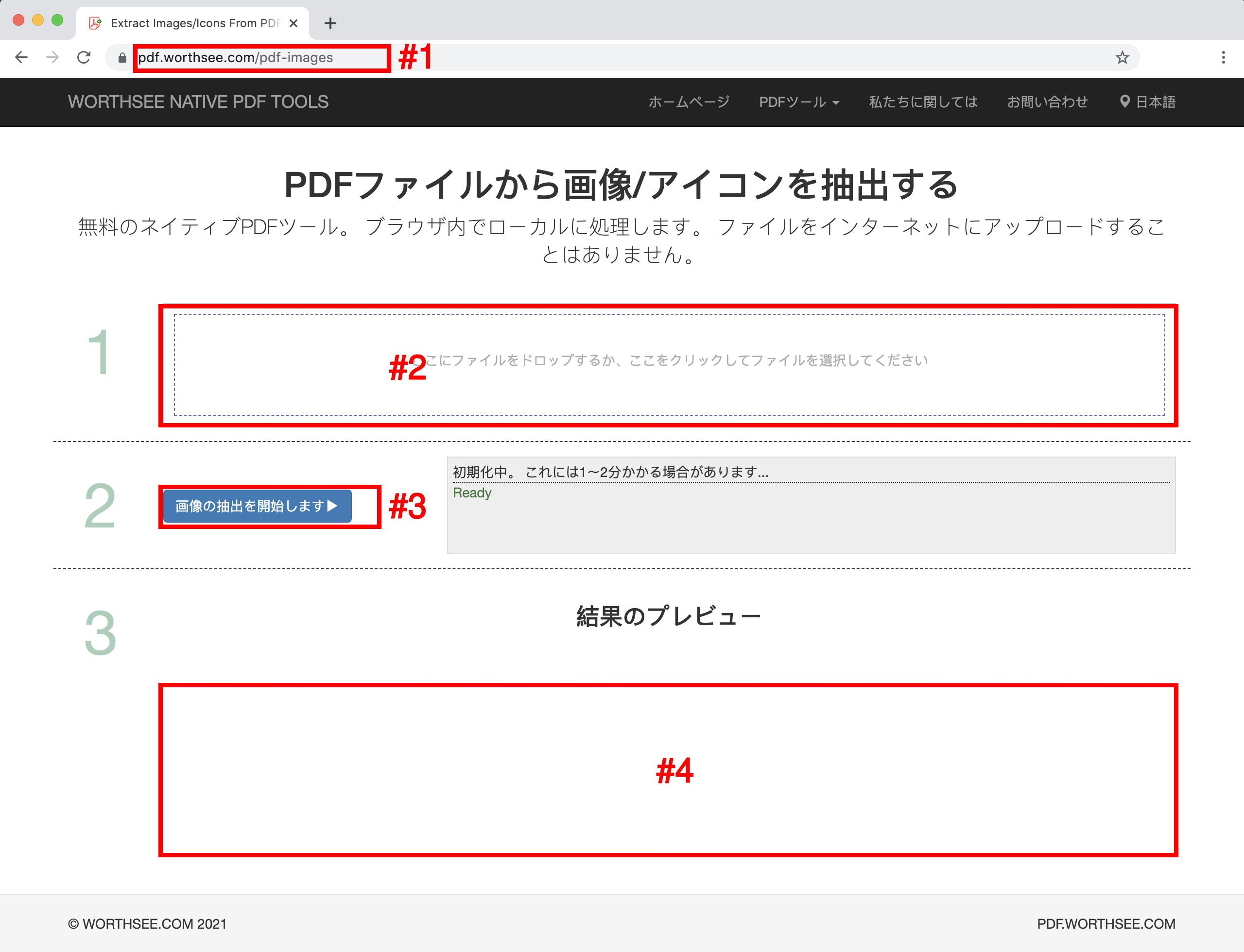
- クリック 範囲 "ここにファイルをドロップするか、ここをクリックしてファイルを選択してください" (として表示 範囲 #2 上の画像で) PDFファイルを選択するには
- ファイルをその領域にドラッグアンドドロップすることもできます
- 必要な数のファイルを選択でき、必要な回数だけ選択できます。
- 選択したファイルがボックスの下に表示されます #2 プレビュー用
- クリック ボタン "画像の抽出を開始します" (として表示 ボタン #3 上の画像で), ファイルが大きい場合は時間がかかる場合があります
- 画像の抽出が完了すると、抽出された画像ファイルが画像に表示されている位置に表示されます #4 (上の画像に示すように), それらをクリックするだけでダウンロードできます
- 選択したファイルが正常に処理されると、ダウンロードリンクが表示されます
- パックで生成されたファイルをZIPファイルにパックすることもサポートしています。生成されたファイルが多すぎる場合は、この機能を使用してそれらをzipファイルにパックし、複数回クリックしてすべてをダウンロードするのではなく、1回だけダウンロードする必要があります。